February 17, 2022

What is a robots.txt file?
A robots.txt file tells search engine crawlers which pages or files the crawler can or can't request from your site. The robots.txt file is a part of the robots exclusion protocol(REP), a group of web standards that regulate how robots crawl the web, access and index content, and serve that content up to users. The robots.txt files indicate whether certain user agents can or cannot crawl parts of the website.
Basic format to write robots.txt file
There is a basic format to add robots.txt file.
User-agent: [user-agent name]Disallow: [URL string not to be crawled]
The above together two lines are considered a complete robots.txt file. However, one robot file can contain multiple lines of user agents & directives. Within a robots.txt file, each set of user-agent directives appears as a discrete set.
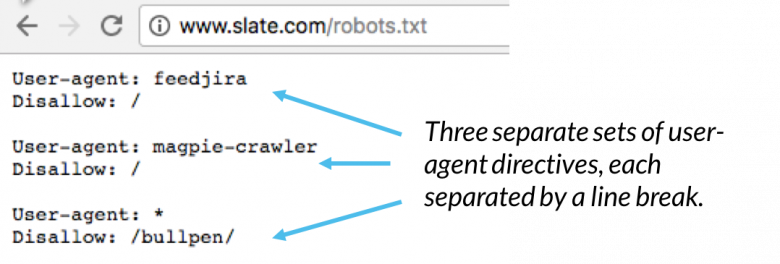
In a robots.txt file with multiple user-agent directives, each disallows or allow the rules only apply to the user agents specified in that particular line break-separated set. So, a crawler will only pay attention to the most specific group instructions.
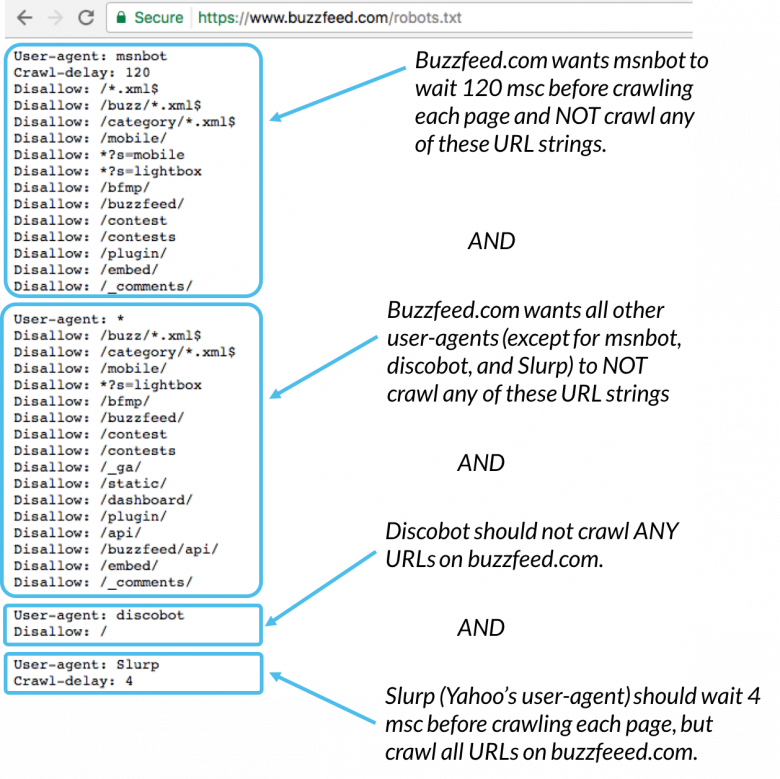
Examples for robots.txt
Let us look at some of the examples of robots.txt
User-Agent: *Disallow: /
This syntax in a robots.txt file tells the crawlers not to crawl any pages on the website on which you have put the syntax.
User-agent: * Disallow:
This syntax will allow all web crawlers access to all content on the website you have included it.
User-agent: Googlebot Disallow: /example-subfolder/
This syntax is only for Google's crawler & it blocks a specific web crawler from a specific folder. This syntax affects the website on the specific page it is applied.
User-agent: BingbotDisallow: /example-subfolder/blocked-page.html
This is for Bing crawlers and it also blocks the specific web crawler from a specific folder.
Search engines have two main jobs
To run the crawlers on the web to discover the content
Indexing that content so that it can be served up to the searchers who are looking for information.
So. ultimately search engines need to crawl millions of websites and content so this crawling sometimes is also known as spiders. So, while spidering the crawlers first look for robots.txt file before moving forward. This is important because this limits the crawlers to crawl on the page. So, if you blocked any information on the crawler then it will move around and index the information that is needed.
Read More: 5 MAINTENANCE TIPS FOR TECHNICAL SEO CHECKLIST
Important information on robots.txt file:
In order to be found, a robots.txt file must be placed in a website's top-level directory.
Robots.txt is a case sensitive: the file must be named "robots.txt".
Some user agents may choose to ignore your robots.txt file. This is especially common with more malware crawlers or email-address scrapers.
The /robots.txt file is publicly available: just add/robots.txt to the end of any root domain to see that website's directives. This means that anyone can see what pages you do or don't want to crawl.
Every subdomain uses a separate robots.txt file.
Robots.txt Syntax
There are five common terms that are likely to see while completing the robots file.
User-agent - This is used to give instructions to the specific web-crawler. A list of most user agents can be found here.
Disallow -The command used to tell a user agent not to crawl on a particular URL.
Allow(Applicable for Google bot) - This command allows the Google bot to access a page or subfolder even though its parent page or subfolder maybe not allowed.
Crawl Delay - How many seconds a crawler should wait before loading & crawling page content.
Sitemap: It is used to call out the location of any XML sitemaps associated with this URL.
Read More: How To Make Your Site More Visible on Google
Pattern-Matching
Robots.texts allows the use of pattern matching to cover a range of possible URL options. Google and Bing both honor two regular expressions that can be used to identify pages or subfolders that SEO wants to be excluded. These two characters are the asterisk(*) & the dollar sign ($). Google offers a great list of possible pattern-matching syntax which you can see for better understanding.
* is a wildcard that represents any sequence of characters
$ matched the end of the URL.
Where does the Robot.txt file go?
At whatever point they go to a website, web indexes and other web-slithering robots (like Facebook's crawler, Facebot) know to search for a robots.txt document. In any case, they'll just search for that record in one explicit spot: the primary index (normally your root area or landing page). In the event that a client operator visits www.example.com/robots.txt and doesn't discover a robot's document there, it will expect the site doesn't have one and continue with creeping everything on the page (and possibly on the whole site). Regardless of whether the robots.txt page existed at, state, example.com/record/robots.txt or www.example.com/landing page/robots.txt, it would not be found by client specialists and in this way, the site would be treated as though it had no robots document by any stretch of the imagination.
So as to guarantee your robots.txt document is found, consistently remember it for your primary catalog or root space.
Why do you need robots.txt?
Robots.txt documents control crawler access to specific zones of your site. While this can be hazardous in the event that you incidentally refuse Googlebot from creeping your whole site (!!), there are a few circumstances where a robots.txt document can be helpful.
Some normal use cases include:
Keeping copy content from showing up in SERPs (note that meta robots are regularly a superior decision for this)
Keeping whole areas of a site private (for example, your building group's organizing site)
Keeping interior query items pages from appearing on an open SERP
Determining the area of sitemap(s)
Forestalling web crawlers from ordering certain documents on your site (pictures, PDFs, and so on.)
Indicating a creeping delay so as to keep your servers from being over-burden when crawlers load numerous bits of substance on the double
In the event that there are no territories on your site to which you need to control client operators to get to, you may not require a robots.txt record by any stretch of the imagination.
Checking if you have a robots.txt file
Not sure if you have a robots.txt file? Simply type in your root domain, then add /robots.txt to the end of the URL. For instance, Moz’s robots file is located at moz.com/robots.txt.
If no .txt page appears, you do not currently have a (live) robots.txt page.
Read More: How to form an effective on-page SEO strategy
SEO Best Practices
Ensure you're not hindering any substance or areas of your site you need to have crept.
Connections on pages obstructed by robots.txt won't be followed. This implies 1.) Unless they're additionally connected from other web crawler open pages (for example pages not blocked by means of robots.txt, meta robots, or something else), the connected assets won't be slithered and may not be filed. 2.) No connection value can be passed from the blocked page to the connection goal. In the event that you have pages to which you need the value to be passed, utilize an alternate blocking component other than robots.txt.
Try not to utilize robots.txt to forestall touchy information (like private client data) from showing up in SERP results. Since different pages may interface straightforwardly to the page containing private data (along these lines bypassing the robots.txt orders on your root space or landing page), it might, in any case, get filed. On the off chance that you need to obstruct your page from list items, utilize an alternate technique like secret key insurance or the no-index meta mandate.
Some web crawlers have various client operators. For example, Google utilizes Googlebot for natural quest and Googlebot-Image for picture search. Most client operators from a similar web index adhere to similar standards so there's no compelling reason to determine mandates for every one of a web index's various crawlers, however, being able to do so allows you to adjust how your webpage content has crept.

A web crawler will store the robots.txt substance, however, as a rule, refreshes the reserved substance at any rate once every day. In the event that you change the document and need to refresh it more rapidly than is happening, you can present your robots.txt URL to Google.
Read More: Robots.txt File Helps in SEO, But How? – Let’s Check!
Robots.txt vs meta robots vs x-robots
So many robots! What’s the difference between these three types of robot instructions? First off, robots.txt is an actual text file, whereas meta and x-robots are meta directives. Beyond what they actually are, the three all serve different functions. Robots.txt dictates site or directory-wide crawl behavior, whereas meta and x-robots can dictate indexation behavior at the individual page (or page element) level.
Recent Posts



























ARE YOU A LEADING SEO SERVICE PROVIDER?
Get listed in world's largest SEO directory today!
Directory listing counter is continuously increasing, be a part of it to gain the advantages, 10314 Companies are already listed.
